Another blog about home automation. We added Somfy IO motorized rolling shutters to our house recently with a Situo 5 IO remote to control them. But what about controlling these rolling shutters with a Raspberry Pi, preferably without an expensive hub? I did some tinkering and found a much cheaper solution.
Somfy IO or RTS
Somfy uses two types of wireless control for motorized rolling shutters: RTS and io-homecontrol. RTS stands for Radio Technology Somfy and uses the open 433 MHz radiofrequency for one-way control. Io-homecontrol is the newer two-way wireless technology. This technology is more secure and more reliable, but this also means that it is more difficult to control with products like a Raspberry Pi.
If you have rolling shutters with an RTS wireless receiver you should look for blogs about Raspberry Pi and rf433. This blog is about controlling Somfy IO rolling shutters with a Raspberry Pi. This solution won’t work with RTS rolling shutters.
What do you need?
Well, Somfy motorized rolling shutters and a Raspberry Pi of course. But what else? You’ll find a small shopping list below.
Do you need a hub?
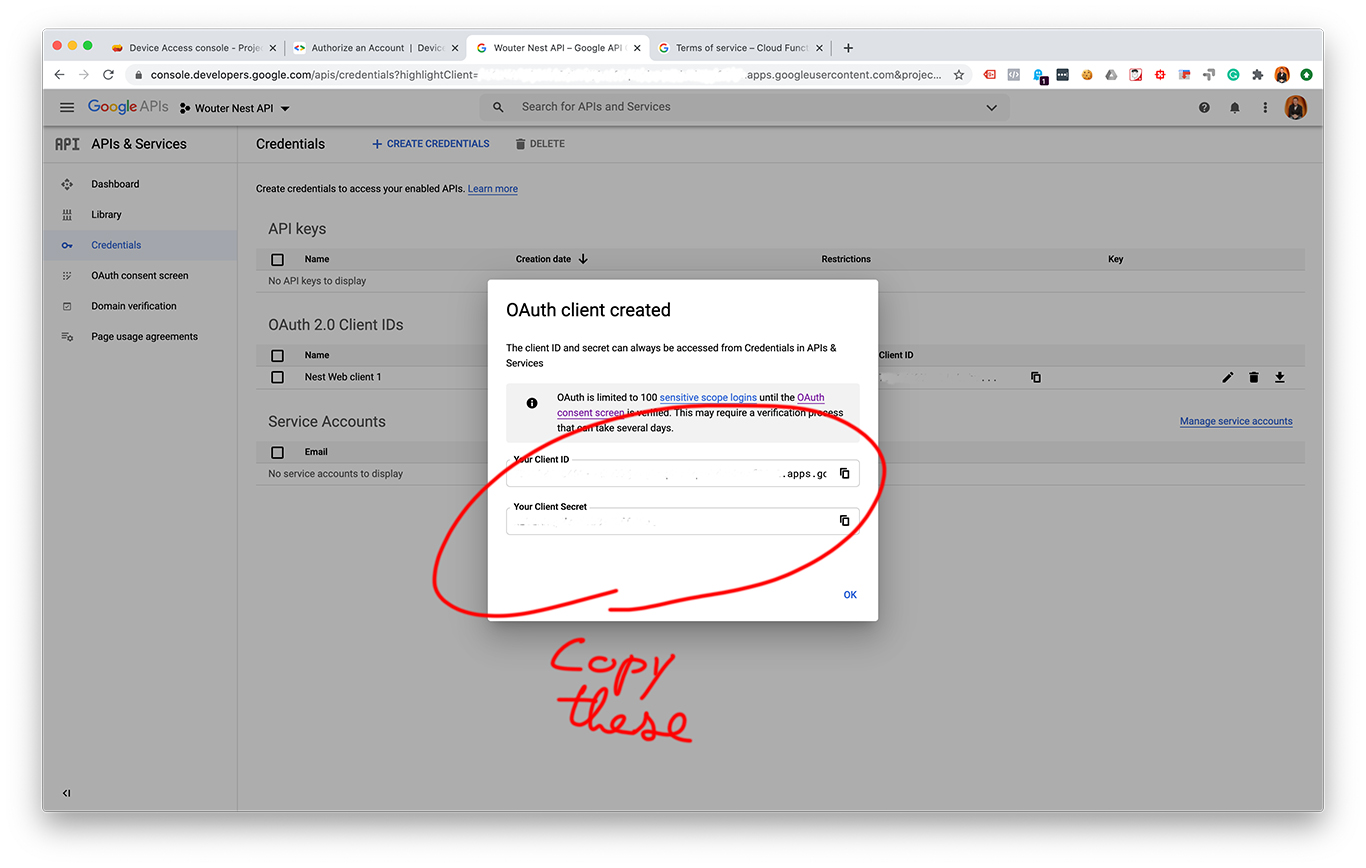
Somfy offers two devices for smart home control of their rolling shutters: the TaHoma hub and the Connexoon io hub. The TaHoma costs about 300 euro and the Connexoon about 170 euro. That’s quite expensive! I already use a Raspberry Pi to control most of my smart home devices and I don’t want to add another hub just to move my rolling shutters. I want to control my rolling shutters without a hub.
Other requirements
I did some Google searches and I found the Somfy Izymo transmitter module. This module is meant for people who already have a wired push-button or rocker switch that they want to transform into an io control. When I got this module it cost about 35 euro, but the price has gone up a bit to about 50 euro.

As you’ll see below, you’ll also need a relay with at least two channels. I used this two-channel relay that cost 6,95 euro.

And finally, you’ll need some wires to connect the Raspberry Pi, the Izymo module, and the relay. You could also use a breadboard or a small terminal block to make connections without soldering. This shouldn’t cost much. I had this stuff lying around from other projects.
You’ll also need a remote to pair the Izymo transmitter to the rolling shutters. You’ll only need to do this once and you can still use the remote like a regular remote afterward.
So here’s your shopping list:
- Raspberry Pi
- Somfy Izymo transmitter module
- Two-channel relay module
- Some wires
- Breadboard (optional)
Even cheaper option
During my search for a solution, I also found some blogs about soldering a Somfy remote directly to an Arduino or a Raspberry Pi. Since a single remote is a bit cheaper than the Izymo module this option will be a bit cheaper altogether. I did not choose this option, because I don’t want to butcher a remote for this. But it is an option.
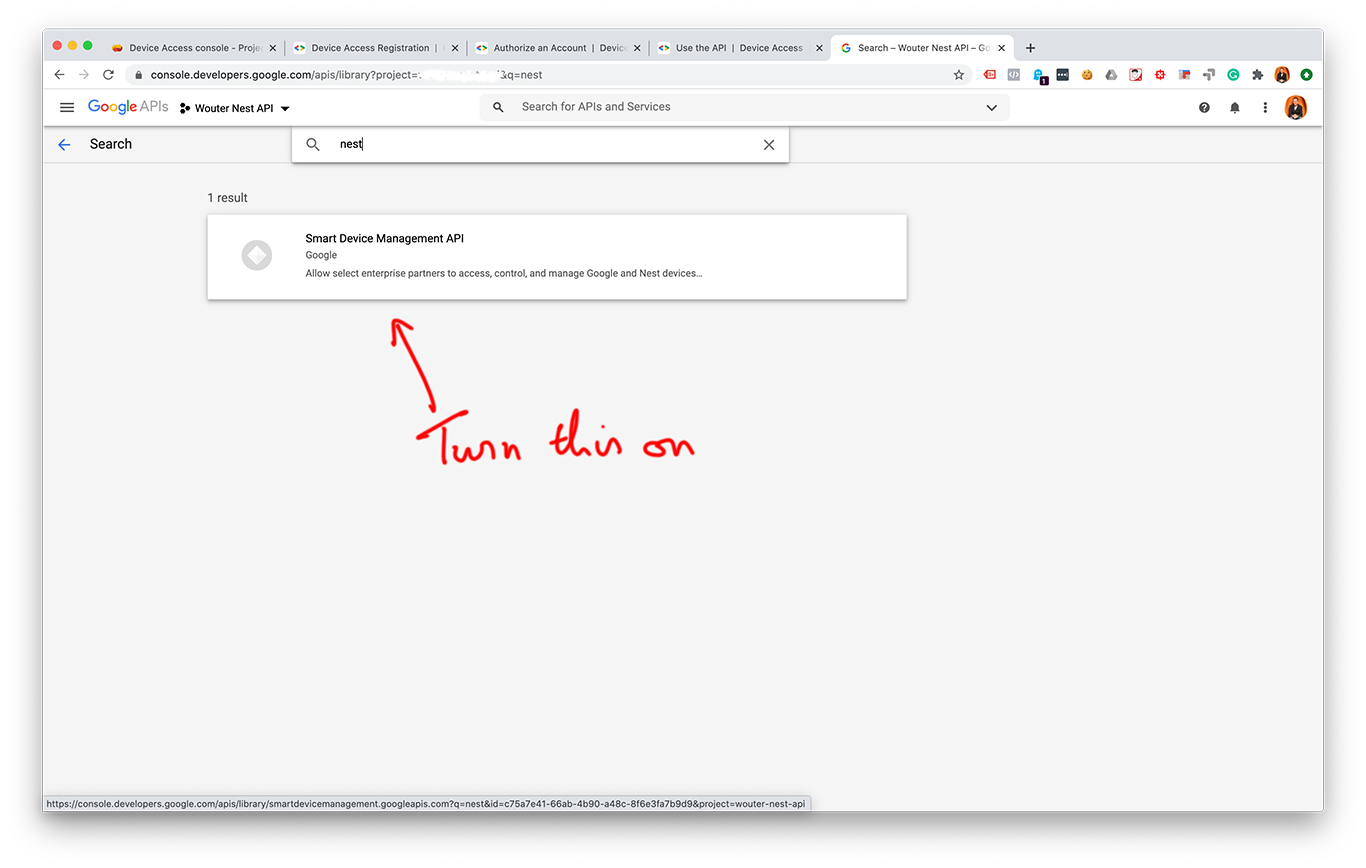
Pairing the transmitter
Before you can use the Izymo transmitter it must be paired with the rolling shutters. The easiest way is to use another remote that is already paired with the rolling shutters. There’s a small button on the back of the Situo 5 IO remote that can be used to put the rolling shutters in association mode. Then briefly press the PROG 1 button (for channel S1) or PROG 2 button (for channel S2) on the transmitter and that should be it.
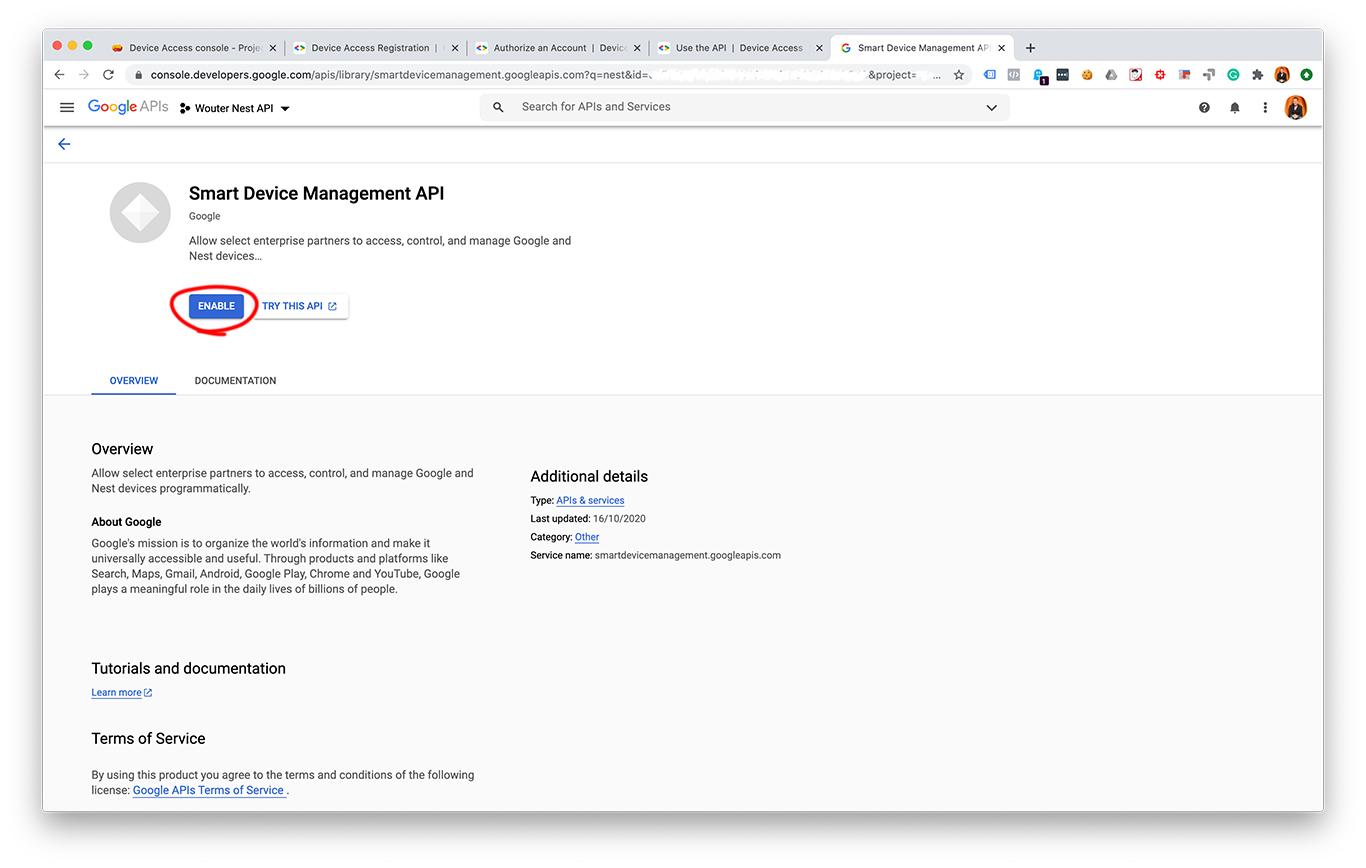
Wiring schematics
As you can see in the picture, the Izymo module has three wires: green, white, and yellow. If you connect the white wire to the yellow wire, the rolling shutters go up. And if you connect the white wire to the green wire, the rolling shutters go down. So to control the rolling shutters, you need to physically ‘switch’ between these wires. That’s what we’ll use the relay for that was mentioned earlier.
The relay has four pins to connect it to the Raspberry Pi. On the relay I got, the VCC pin is connected to 5 volts, the GND pin is connected to ground and the other two pins (IN1 and IN2) are connected to the GPIO pins. In my case, I used pin 13 and 26 as GPIO pins, but feel free to use other pins if that suits your project.

A Python code example
After connecting all the wires we can start writing some code. There are plenty of blogs about using the GPIO pins on a Raspberry Pi with Python. I can recommend this blog if this is your first project: https://pythonprogramming.net/gpio-raspberry-pi-tutorials/. The code below is actually not very different from the example in the other blog.
You can change the pin numbers to correspond with your own project. Then call the function move_shutters() with a direction (‘up’ or ‘down’) and the duration in seconds that you want to move the rolling shutters.
![]()
![]()
import RPi.GPIO as GPIO
import time
GPIO.setmode(GPIO.BCM)
pin_up = 26
pin_down = 13
GPIO.setup(pin_up, GPIO.OUT)
GPIO.setup(pin_down, GPIO.OUT)
GPIO.output(pin_up, GPIO.LOW)
GPIO.output(pin_down, GPIO.LOW)
def move_shutters (direction, sec):
if (direction == 'up'):
GPIO.output(pin_up, GPIO.HIGH)
time.sleep(sec)
GPIO.output(pin_up, GPIO.LOW)
if (direction == 'down'):
GPIO.output(pin_down, GPIO.HIGH)
time.sleep(sec)
GPIO.output(pin_down, GPIO.LOW)
move_shutters('down', 20)
A Nodejs example
The example below is a bit more elaborate. This is what I actually use in my own home automation project. It creates a Router for a Nodejs Express app. I also added some lines to make it work on devices without GPIO pins for testing purposes.