

One of the fun things when you like both data and running is that you can collect loads of data by running with a GPS tracker or a mobile phone. With apps such as Strava, Runkeeper or Endomondo you get all kinds of statistics about your workouts. I’ve been using Endomondo for several years now and when I found this really interesting article by Steven van Dorpe about how to analyze GPS data with Python I wanted to try doing some analysis for myself.
Specifically, in this blog we’ll go through the steps to find the best or fastest section within a workout. For example, if I ran 12 kilometers, started slow and finished fast, what was the time for the fastest 10 kilometers during that entire workout? And what was my fastest 10 kilometer this year for example? Let’s find out!
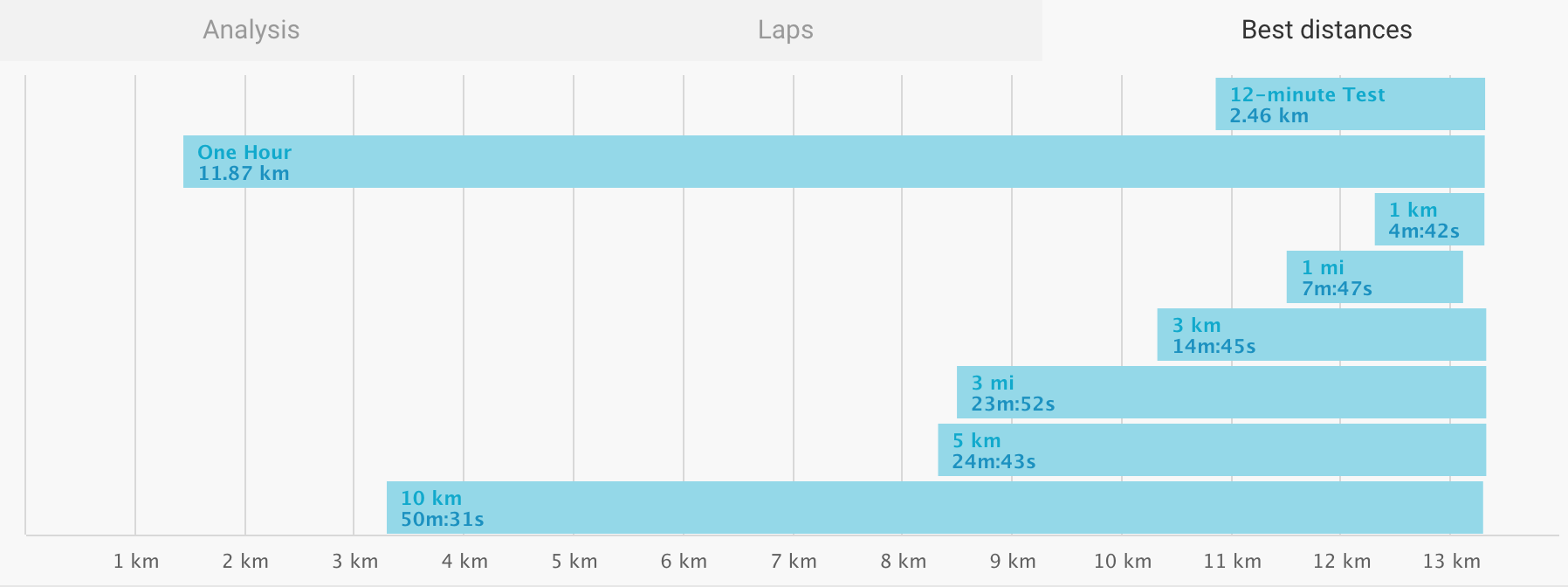
There is this specific chart from Endomondo that I like a lot: my personal best for a specific distance over time. The interesting thing about this graph is that it shows my personal best for a specific distance from within a longer workout.

Unfortunately this graph has some limitations, especially when you’re not a premium (paying) user of Endomondo. The free version only shows personal bests for 5 kilometers or 3 miles. PB’s for other distances are only available for premium users. (I leave it up to you to decide if you find it ethical to replicate some functionality from the premium features.) 😉 And interesting stats such as my PB’s for specific combinations are not available at all, such as my fastest 5K from workouts over 10K over the past 12 months. (Sidenote: I’ve been a paying user for quite some time in the past and I also bought the app for a fixed price many years ago.)
Parsing and preparing the data
Anyway, lets see if we can build on Steven’s instructions to find the fastest 5K, 10K, and so on within a workout. Endomondo and most other running apps let you download your workouts as GPX files. These files contain the data about your GPS location, altitude and time. I use Python and Jupyterlabs Notebooks (which is included with Anaconda) for parsing and analysing these files.
Let’s get coding! The first step is to include some packages:
Then declare some variables and parse the GPX file:
In Steven van Dorpe’s article, all data is added by using data = gpx.tracks[0].segments[0].points but I found that some GPX files contain multiple segments with relevant data, some don’t, some contain multiple segments where the last segment should be omitted, and so on. You should really inspect your data to see what data you need. For recent Endomondo GPX files I found that if the file contains multiple segments, I should import all segments except the last segment, unless the file contains only one segment, because then we need all segments.
For this blog let’s assume you can include all segments. Oh, and let’s also apply some sorting and filling to clean any problems in the data:
So far we’ve been following the instructions from the article by Steven, but from here we’ll be doing some things different. Instead of looping over data to calculate distances I decided to stick with Pandas and use vectorization to try to speed things up. At this point we’re working on a single GPX file, but eventually we may want to loop over a folder with multiple GPX files (270 in my case) and speed suddenly becomes important (as we’ll see later). Using vectorization and the apply() method to calculate distances involved adding some extra columns to the DataFrame with values that are “shifted one row backwards”:
Some GPX files gave me a hard time about timezones. These lines fixed this:
And then the actual calculations for distances and time differences with Pandas apply(). The math behind this is all explained thoroughly in the article by Steven van Dorpe I mentioned earlier. If you’re at this point in this blog and you still haven’t read his article, I can definitely recommend you do this first and then continue with the code below:
Then as a final substep before the actual search for the fastest sections I create a new DataFrame that only contains the columns needed for further calculations to speed things up a little bit more. Here I also add two columns for cumulative sums for these columns.
Finding the actual fastest section
Remember that at the beginning of this blog we created a list with sections? Now it’s time to loop over this list and find the fastest kilometer, fastest 5 kilometer, fastest 5 miles, and so on.
If the current section is longer than the total distance of the entire workout there is no need to do any further analysis and we can skip ahead to the next iteration.
To find the fastest section within the entire workout we must loop over the DataFrame.* For every row we locate the first row further ahead where the cumulative sum of the total distance minus the cumulative distance at this row is greater or equal to the section.
*) I know that looping over a DataFrame is not the best solution in terms of speed. However, I have not found a way to get the same results without this loop. Did you find a faster way to do this? Let me know! 🙂
That’s a lot to take in… 😉 So let me give you an example. Lets say we want to find the fastest 50 meters from the virtual workout below:
| Time | Distance |
| 0 seconds | 0 meters |
| 10 seconds | 10 meters |
| 20 seconds | 25 meters |
| 30 seconds | 35 meters |
| 40 seconds | 45 meters |
| 50 seconds | 55 meters |
| 60 seconds | 60 meters |
| 70 seconds | 70 meters |
| 80 seconds | 85 meters |
| 90 seconds | 90 meters |
- At 0 seconds and 0 meters we find the first row that is 50 meters or more ahead, which is the row at 50 seconds and 55 meters. The speed over this section was (55 meter / 50 seconds) = 1.1 meter per second.
- Then we start at the second row with 10 seconds and 10 meters and find the first row that is 50 meters or more ahead, which is the row at 60 seconds and 60 meters. The speed over this section was ((60 meter – 10 meter) / (60 seconds – 10 seconds)) = 1.0 meter per second.
- Then we start at the third row with 20 seconds and 25 meters and find the first row that is 50 meters or more ahead, which is the row at 80 seconds and 85 meters. The speed over this section was ((80 meters – 25 meters) / (80 seconds – 20 seconds)) = 0.92 meters per second.
- … and so on…
The first iteration with 1.1 meter per second is the fastest section, because it traveled the section of 50 meter with the highest average speed.
This is what this looks like in code:
The result in df_final looks something like this:
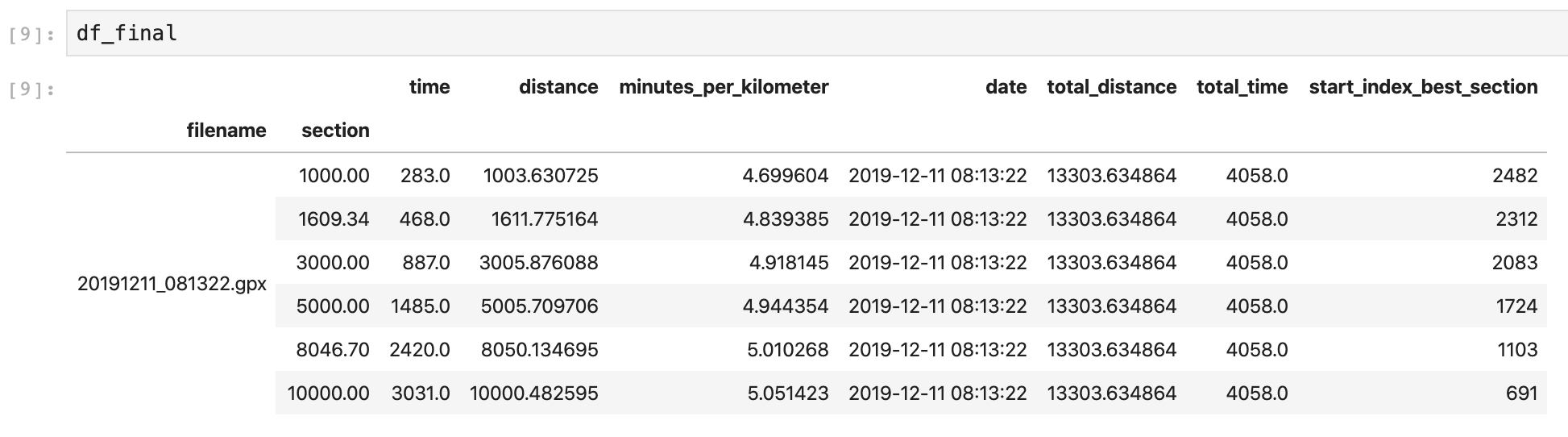
| Section | Calculations based on time | Endomondo |
| 1 km | 283 seconds = 4:43 | 4:42 |
| 1 mi | 468 seconds = 7:48 | 7:47 |
| 3 km | 887 seconds = 14:47 | 14:45 |
| 5 km | 1485 seconds = 24:45 | 24:43 |
| 10 km | 3031 seconds = 50:31 | 50:31 |
As you can see, our calculations are pretty close, but not exactly the same. When you study the screenshot of the DataFrame more closely, the distance of each section is also just a little bit more than the actual section. So for the time it took to travel 3 km, I actually travelled 3.005 km. This would explain why we got one or two seconds more for each section. Let’s see if the results are better when we account for this by using the average speed over the fastest section for our calculations:
| Section | Calculations based on minutes per kilometer | Endomondo |
| 1 km | 4.699604 * 1 = 4:42 | 4:42 |
| 1 mi | 4.839385 * 1.60934 = 7:47 | 7:47 |
| 3 km | 4.918145 * 3 = 14:45 | 14:45 |
| 5 km | 4.944354 * 5 = 24:43 | 24:43 |
| 10 km | 5.051423 * 10 = 50:31 | 50:31 |
Now my calculations exactly match the results from Endomondo! Nice!
Working with multiple GPX files
So far we’ve used only a single GPX file, but for statistics like the fastest 10K over the past 12 months we need to import all workouts during that timeframe. For my personal project I wanted to include all my workouts. So that’s what I did!
The following code is a combination of all the code snippets above, but it also collects all GPX files included in a subfolder /tracks/ and loops over all of them. This might take a while to run though, so make sure not to include too many files.
Final result
With the output data in df_final we can continue to make plots, extract data and so on. With just a few more lines of code I can for example find out how far I’ve ran on my current shoes so far (709 km), make scatter plots of distance and date (apparently I had a habit of stopping at exactly 10 kilometers in 2016) or make my own version of the Endomondo graph at the top of this blog (it’s not as fancy yet, but close).


So this is it! We’ve looped over a DataFrame to find the fastest sections from a list of GPX files. Perhaps I’ll build on this script to build a nice dashboard for my running activities, but that’s something for later.
Some final thoughts
Probably my biggest “concern” with this entire endeavour is the contents of the GPX files compared to the Endomondo app and interface. As it turns out, the total distance of the workouts from the GPX files is just slightly lower compared to what Endomondo reports. And I know this discrepancy is not caused by my calculations, because I found out that if I would upload a GPX file back to Endomondo it would also have a lower total distance!
An example workout sums up to a maximum total distance of 13303 meters or 13.30 kilometers in my calculations. According to the Endomondo interface, this workout should actually be 13.32 kilometers. However, when I upload this GPX file back to Endomondo it would only be 13.29 kilometers. Weird…


Also, I learned a lot about the importance of speed with this project. The original instructions by Steven van Dorpe were too slow for my use case (but very educational nonetheless). But even with all the vectorization and apply() methods that I could get to work in this project it will still take minutes or more to loop over multiple GPX files. So keep this in mind if you’re trying to build on my examples. 🙂
Hi Wouter,
I used parts of your code to calculate Cooper test results for me from my .gpx file(s). I use cumulative distance and cumulative time. And then export such a dataframe to csv. In Excel I am calculating 720 seconds time difference and then check what the distance delta was. In general I think it’s a missing thing to analyse .gpx files in this way. Something that I couldn’t really find anywhere over the Web nor in any other program.
Best,