Google recently released its Device Access API. This article is a short explanation of how to access and use this API to control a Google Nest thermostat.
We moved to a new house a few months ago and the previous owners left their thermostat behind. This thermostat turned out to be a brand new Nest smart thermostat. Of course, I wanted to connect this smart device to my home automation. But unfortunately, after some searching, I found out that most connections were deprecated after Google acquired Nest a couple of years ago, along with the API access for consumers. The only option was to sign up for a waitlist.
But to my surprise, I got an email from Google a couple of weeks ago! The Device Access Console is now available to individual consumers as well as commercial partners. I wanted to find out if I could control my Google Nest thermostat so I wrote some Python code for this.

Get started with Google documentation
Google has written some quite elaborate documentation about all the steps needed to access the API. The purpose of this article is not to rewrite their help articles. These articles will get you started:
- https://developers.google.com/nest/device-access/registration
- https://developers.google.com/nest/device-access/get-started
- https://developers.google.com/nest/device-access/authorize
- https://developers.google.com/nest/device-access/use-the-api
- https://developers.google.com/nest/device-access/api/thermostat
And you’ll also need these links:
How much does it cost?
Before creating your first project, you must pay a one-time, non-refundable fee (US$5) per account. There can also be cost involved by using Google Cloud services, but I have been polling my thermostat every 5 minutes for a couple of weeks now without cost.
Gather all requirements
It’s tempting to begin creating a Device Access project right away (I did so too), but I found out that it is probably easier to get all the necessary prerequisites first. Before you can start coding you should follow these steps:
- Create a Google Cloud Console project at console.cloud.google.com
- Create Cloud Console oAuth 2.0 credentials
- Set a redirect URI
- Turn on the Smart Device Access API
- Create a Device Access project at console.nest.google.com
I made some screenshots from each step:
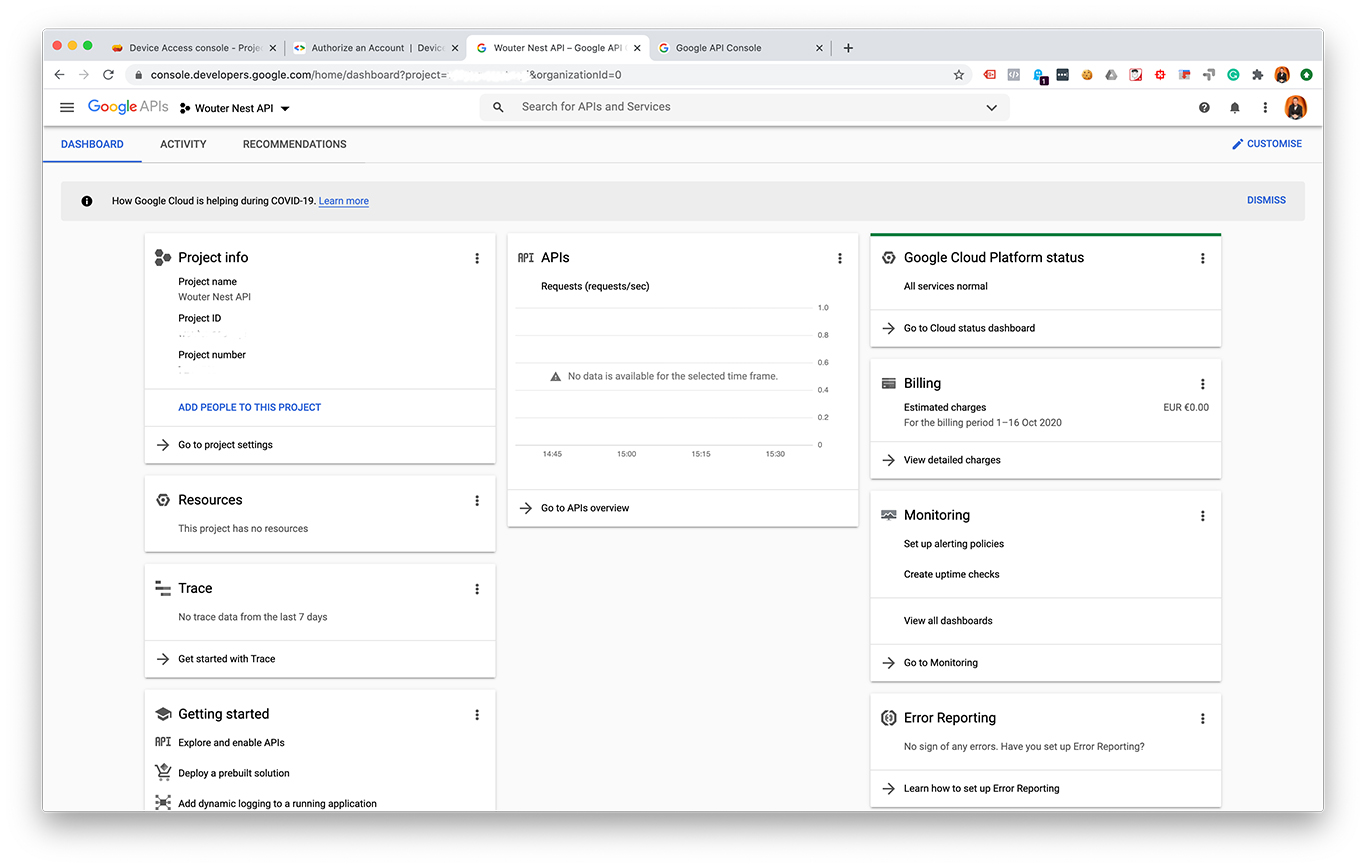
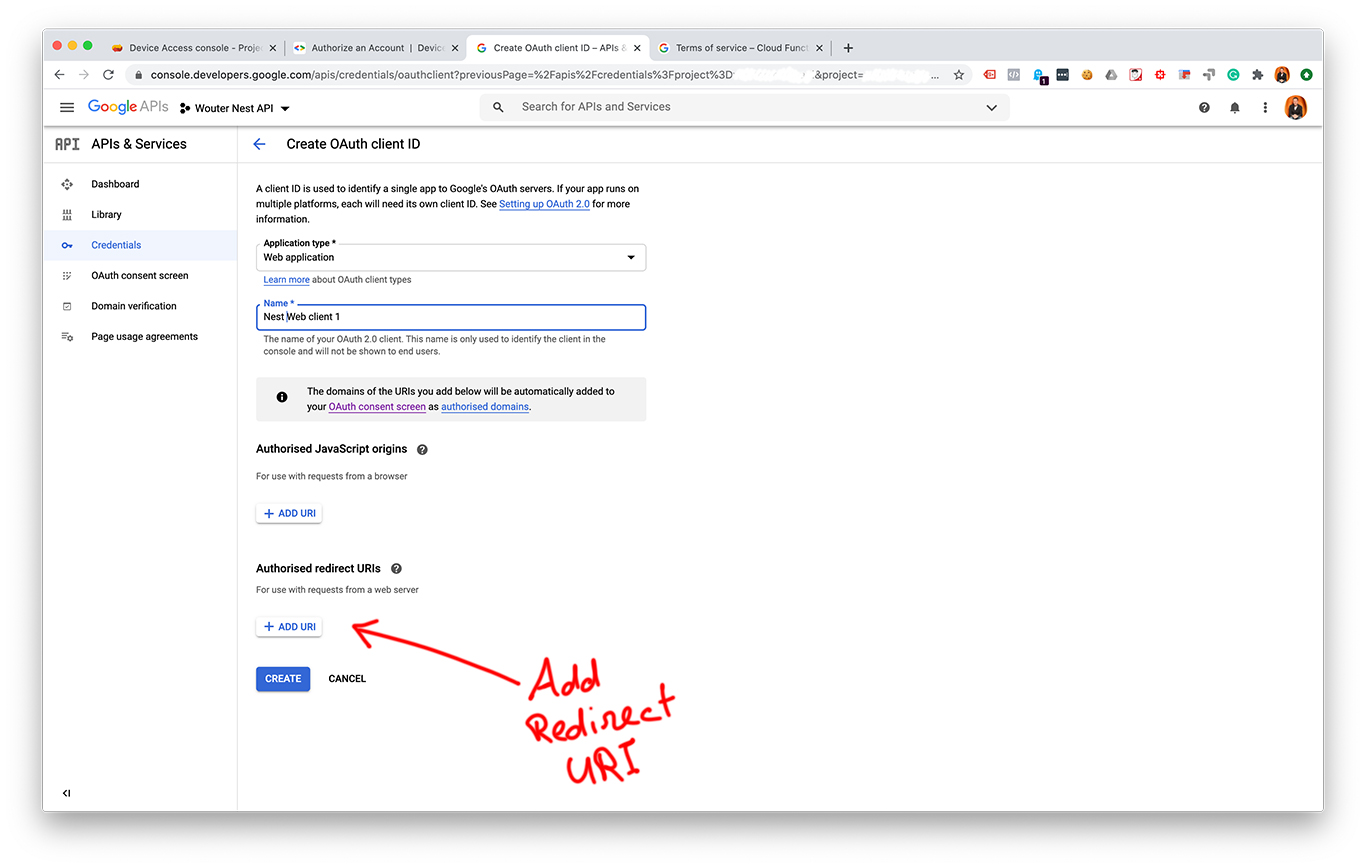
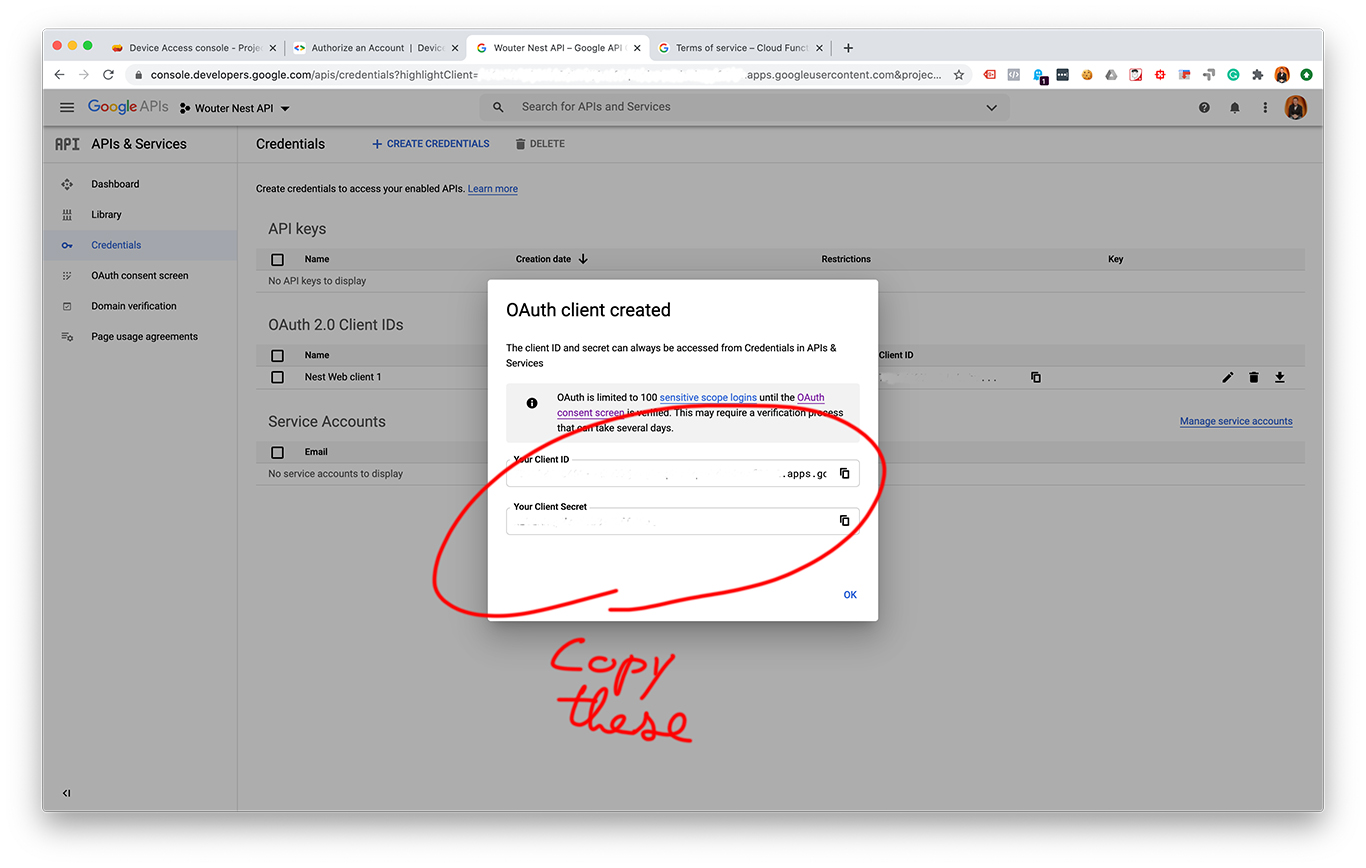
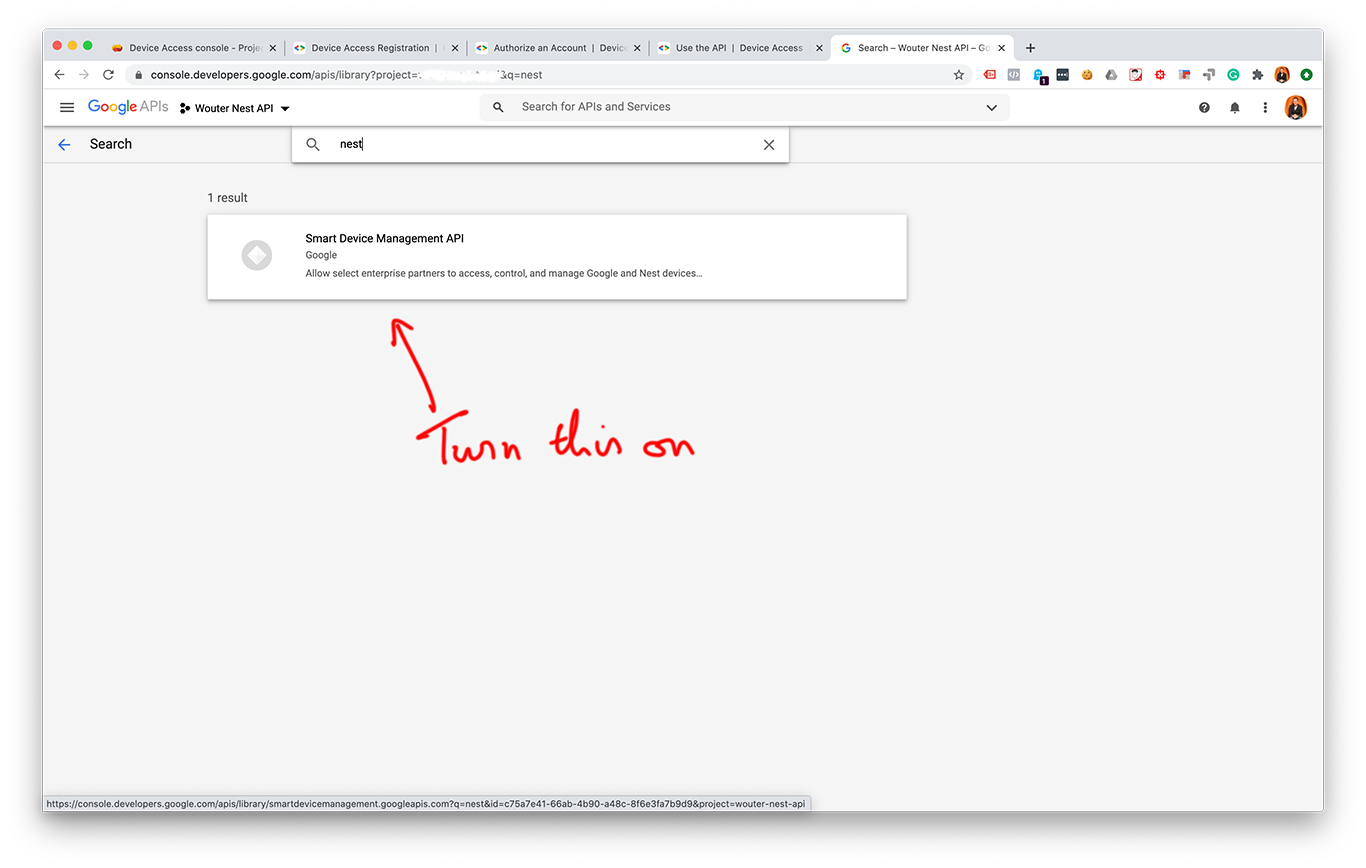
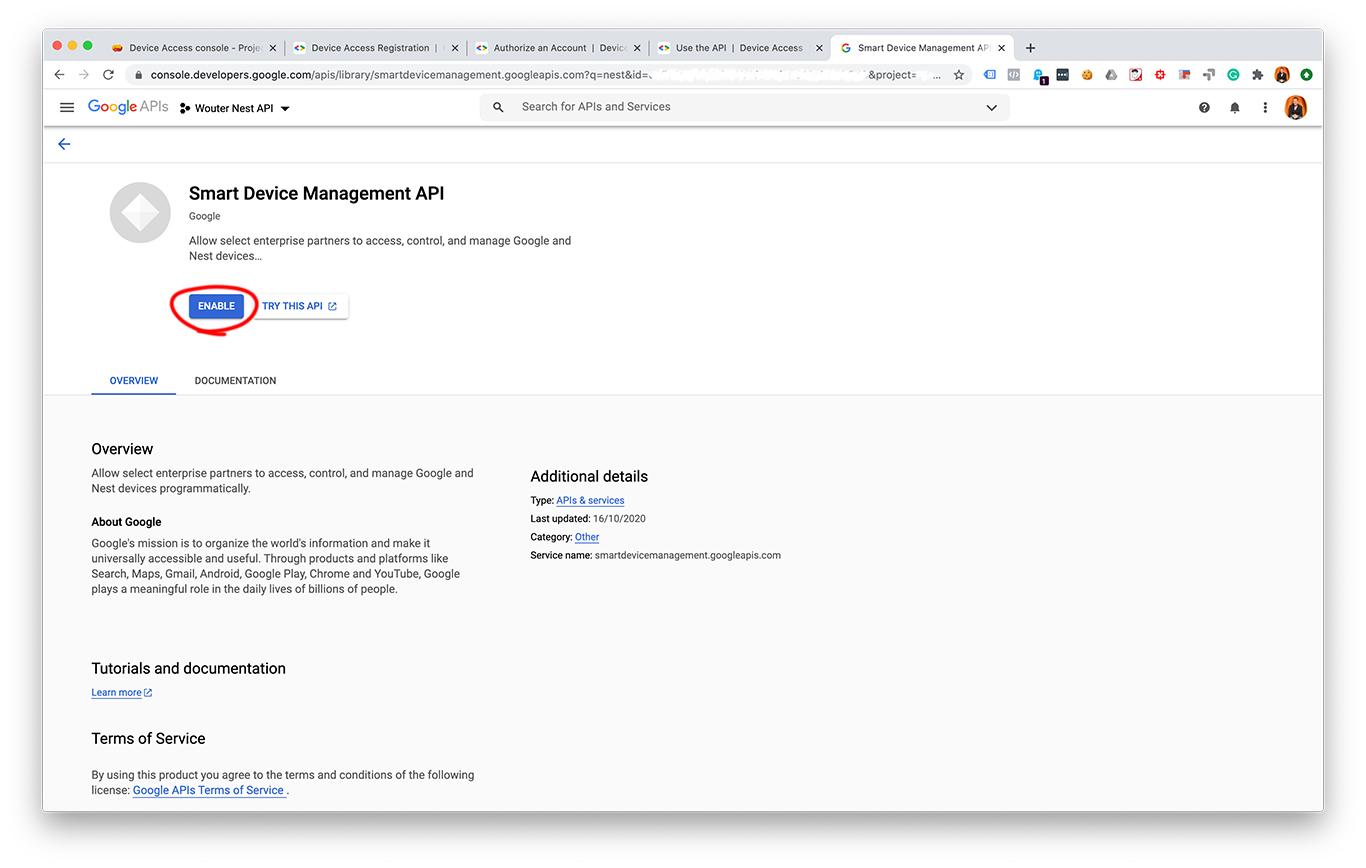
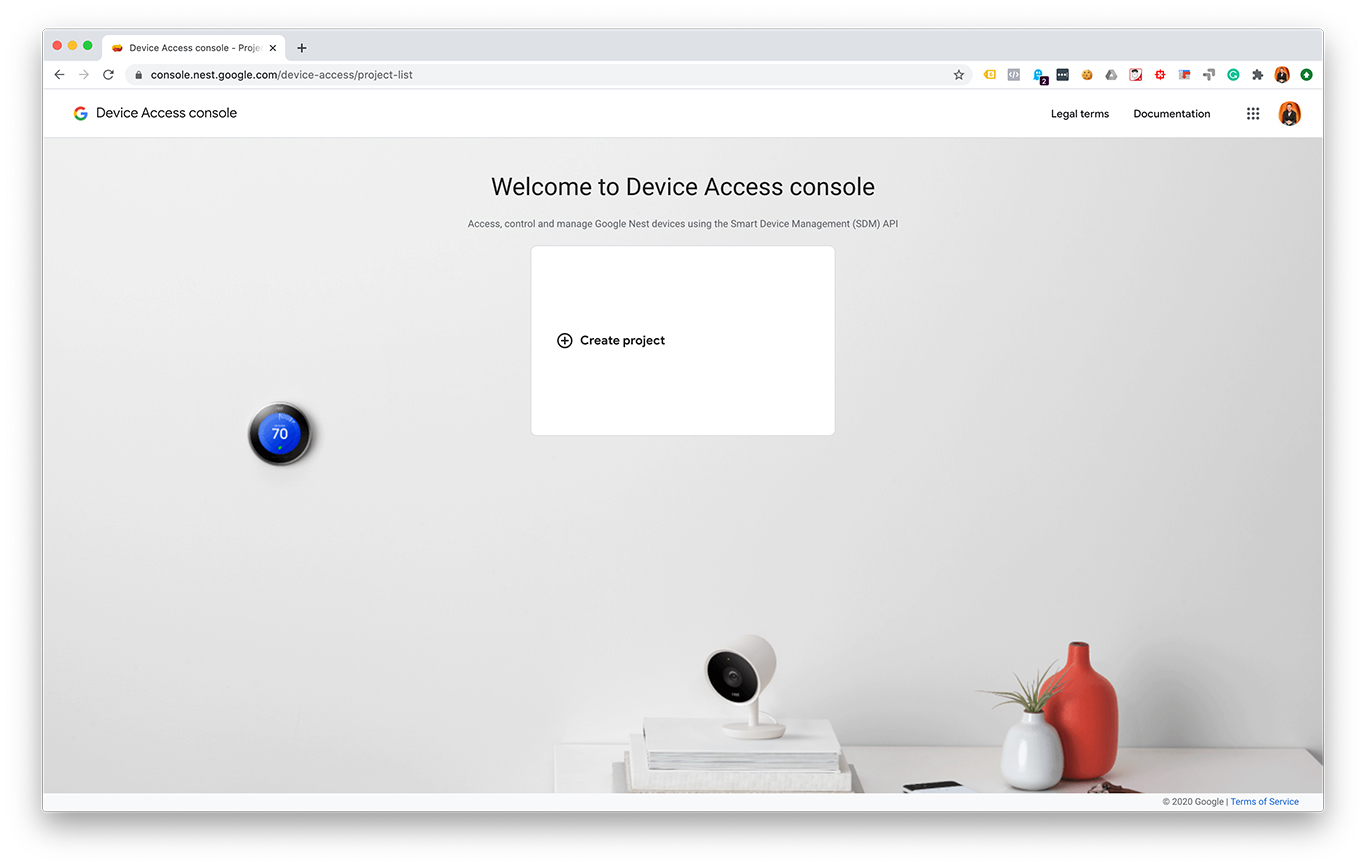
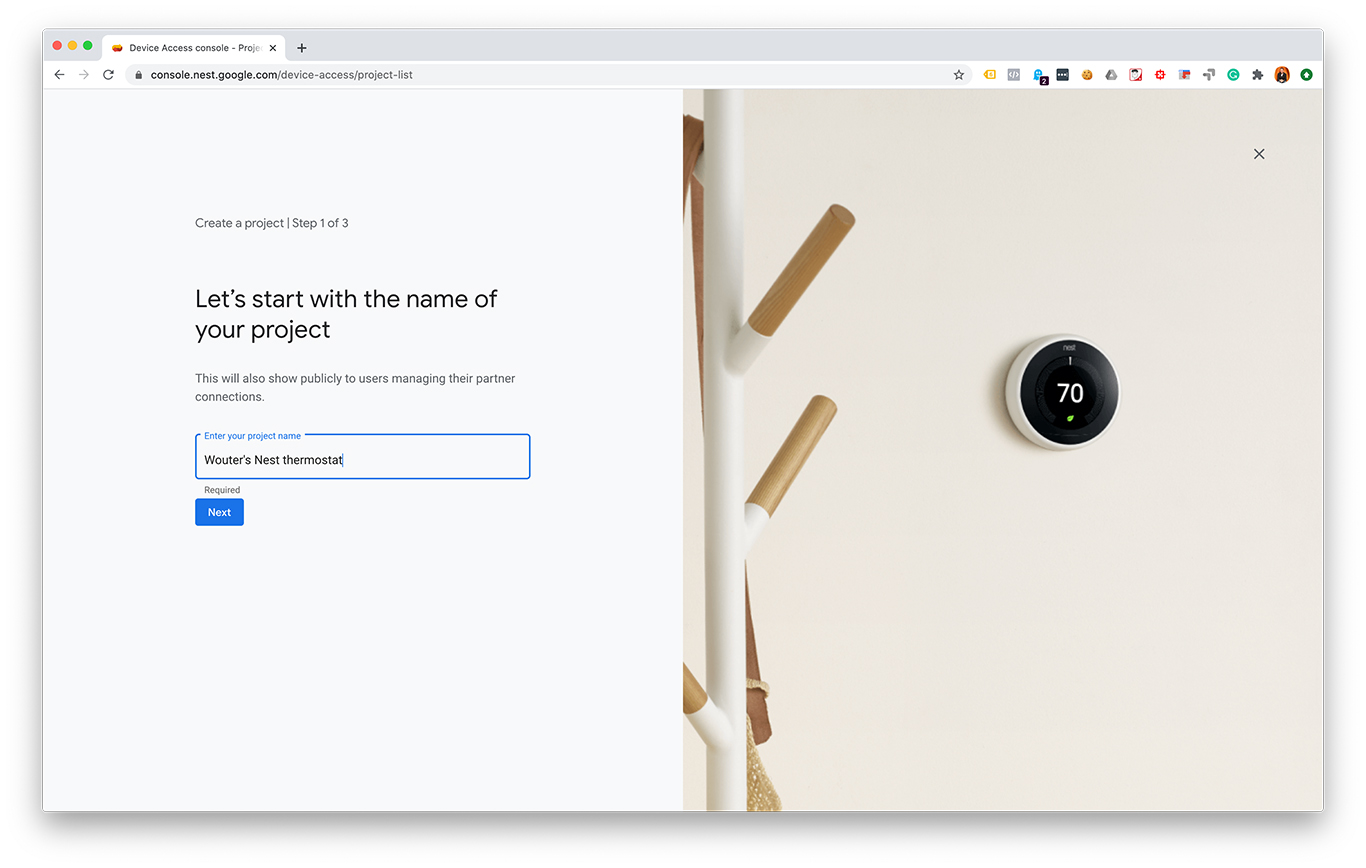
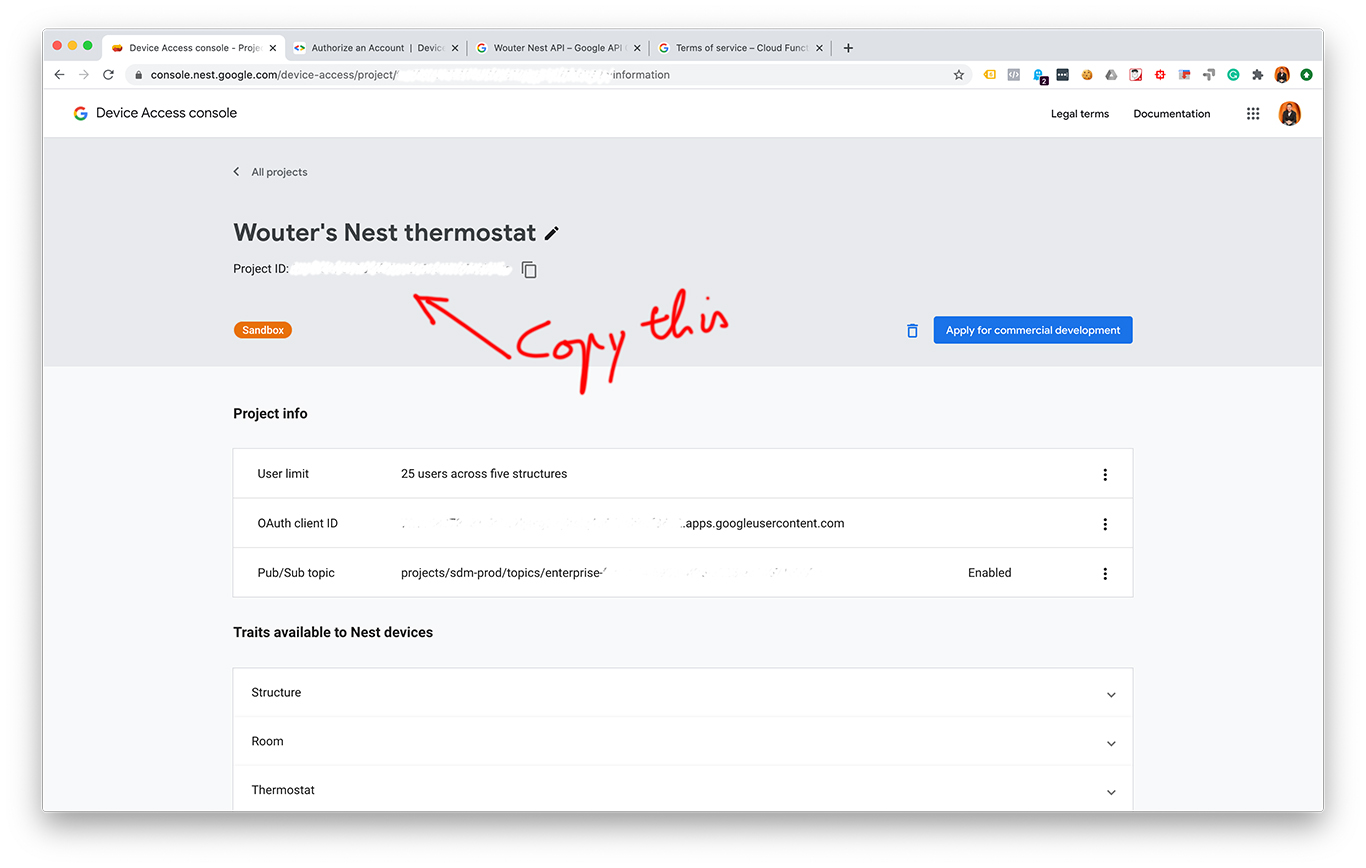
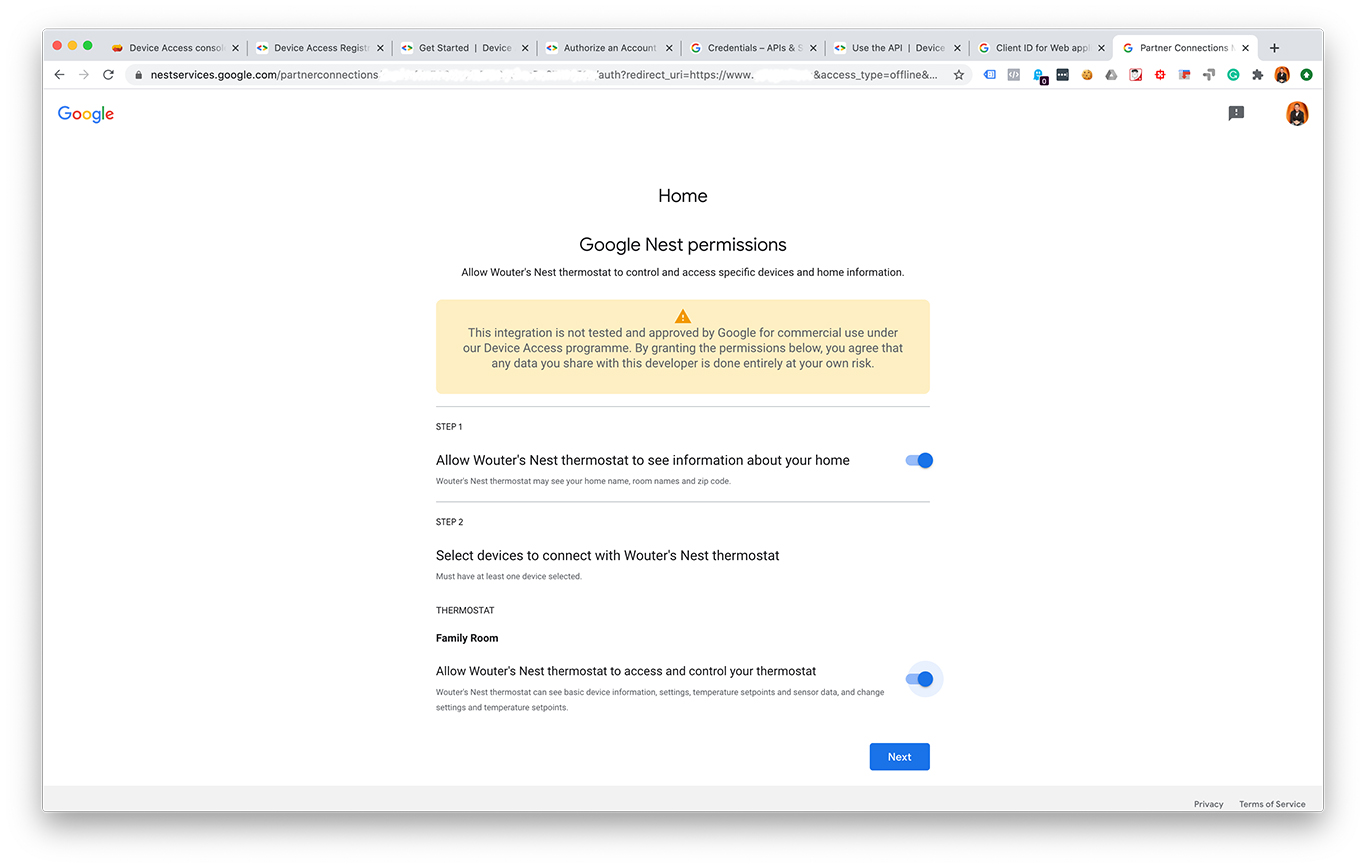
After creating an OAuth 2.0 client ID and a Device Access project you should have these values:
- A project ID. You can find this in your Device Access console.
- A client ID. You can find this with your OAuth credentials.
- A client secret. You can find this with your OAuth credentials.
- A redirect URI. This URI can be almost any URL you want, as long as this URL matches a URI that is entered as an authorized redirect URI in your Cloud Console project.
Some example API calls with Python
Now we can start making API calls! Below is a Jupyter Notebook that walks through all the steps to control a Nest thermostat.
You can also make a copy of the Google Colab notebook I made.
![]()
![]()
project_id = 'your-project-id'
client_id = 'your-client-id.apps.googleusercontent.com'
client_secret = 'your-client-secret'
redirect_uri = 'https://www.google.com'
url = 'https://nestservices.google.com/partnerconnections/'+project_id+'/auth?redirect_uri='+redirect_uri+'&access_type=offline&prompt=consent&client_id='+client_id+'&response_type=code&scope=https://www.googleapis.com/auth/sdm.service'
print("Go to this URL to log in:")
print(url)
After logging in you are sent to URL you specified as redirect_url. Google added a query to end that looks like this: ?code=.....&scope=... Copy the part between code= and &scope= and add it below:
code = '4/add-your-code-here'
Get tokens¶
Now we can use this code to retrieve an access token and a refresh token:
# Get tokens
import requests
params = (
('client_id', client_id),
('client_secret', client_secret),
('code', code),
('grant_type', 'authorization_code'),
('redirect_uri', redirect_uri),
)
response = requests.post('https://www.googleapis.com/oauth2/v4/token', params=params)
response_json = response.json()
access_token = response_json['token_type'] + ' ' + str(response_json['access_token'])
print('Access token: ' + access_token)
refresh_token = response_json['refresh_token']
print('Refresh token: ' + refresh_token)
Refresh access token¶
The access token is only valid for 60 minutes. You can use the refresh token to renew it.
# Refresh token
params = (
('client_id', client_id),
('client_secret', client_secret),
('refresh_token', refresh_token),
('grant_type', 'refresh_token'),
)
response = requests.post('https://www.googleapis.com/oauth2/v4/token', params=params)
response_json = response.json()
access_token = response_json['token_type'] + ' ' + response_json['access_token']
print('Access token: ' + access_token)
Get structures and devices¶
Now lets get some information about what devices we have access to and where these are "located". Devices are part of a structure (such as your home). We can get information about the structures we have access to:
# Get structures
url_structures = 'https://smartdevicemanagement.googleapis.com/v1/enterprises/' + project_id + '/structures'
headers = {
'Content-Type': 'application/json',
'Authorization': access_token,
}
response = requests.get(url_structures, headers=headers)
print(response.json())
But we can also directly retrieve the devices we have access to:
# Get devices
url_get_devices = 'https://smartdevicemanagement.googleapis.com/v1/enterprises/' + project_id + '/devices'
headers = {
'Content-Type': 'application/json',
'Authorization': access_token,
}
response = requests.get(url_get_devices, headers=headers)
print(response.json())
response_json = response.json()
device_0_name = response_json['devices'][0]['name']
print(device_0_name)
Get device stats¶
For this example I simply took the first item of the array of devices. I assume most people probably have one Nest thermostat anyway.
The name of a device can be used to retrieve data from this device and to send commands to it. Lets get soms stats first:
# Get device stats
url_get_device = 'https://smartdevicemanagement.googleapis.com/v1/' + device_0_name
headers = {
'Content-Type': 'application/json',
'Authorization': access_token,
}
response = requests.get(url_get_device, headers=headers)
response_json = response.json()
humidity = response_json['traits']['sdm.devices.traits.Humidity']['ambientHumidityPercent']
print('Humidity:', humidity)
temperature = response_json['traits']['sdm.devices.traits.Temperature']['ambientTemperatureCelsius']
print('Temperature:', temperature)
Set thermostat to HEAT¶
And last but not least, lets send some commands to our thermostat. The cell below contains the code to set the mode to "HEAT":
# Set mode to "HEAT"
url_set_mode = 'https://smartdevicemanagement.googleapis.com/v1/' + device_0_name + ':executeCommand'
headers = {
'Content-Type': 'application/json',
'Authorization': access_token,
}
data = '{ "command" : "sdm.devices.commands.ThermostatMode.SetMode", "params" : { "mode" : "HEAT" } }'
response = requests.post(url_set_mode, headers=headers, data=data)
print(response.json())
Set a new temperature¶
And finally we can set a temperature by executing this command:
set_temp_to = 21.0
# Set temperature to set_temp_to degrees
url_set_mode = 'https://smartdevicemanagement.googleapis.com/v1/' + device_0_name + ':executeCommand'
headers = {
'Content-Type': 'application/json',
'Authorization': access_token,
}
data = '{"command" : "sdm.devices.commands.ThermostatTemperatureSetpoint.SetHeat", "params" : {"heatCelsius" : ' + str(set_temp_to) + '} }'
response = requests.post(url_set_mode, headers=headers, data=data)
print(response.json())